
OpenAI
It's year 2023, the AI bots will take over the "world" so here is a template for it for bOS too...Kodu-Http (OpenAI) (1.2).bos
Right now it works just as a outdated google search with better logic or smth. Somehow the image generator crashes the http driver. Remember everything is in beta.
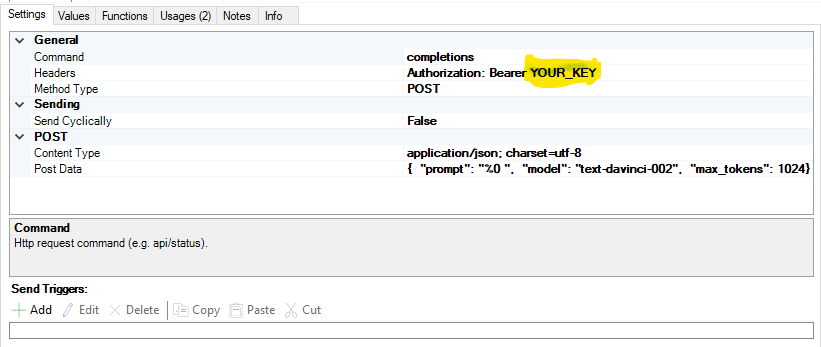
To get it working you need to make a account for OpenAI and generate your API key.
1. insert it here - for both completions and image generator commands YOUR_KEY.
2. You can ask the AI your question and it should respond. Made a TTS for it's answers too so its extra creepy.
FYI it's not as good as the web page bot - for longer answers sometimes it doesn't give out the full info and I've seen that some of codes may go missing. In theory you can make it give you suggestions automatically too. If it gives you a BadRequest error see if the input is all in one line. It does not like it when some text is on a new line.
Happy new year!
Customer support service by UserEcho

Glad to see someone using OpenAI...
Been using and exploring ChatGPT and it's kind of creepy at a certain point what it can do....generating html code, arduino code, etc, and with more or less fiddling it almost gets there. Even creating random songs with random themes.
Hopefully we can use AI / ML in the near future to predict stuff for our smart homes and projects. That's my goal, to use AI in the future to create stuff like real life presence simulation, predict schedules, and endless possibilities.
Best regards, and happy new year
I got the image generator working. It may take longer time to generate images so I upped the timeout value. Don't know yet how to input those links it generated to a bOS browser. So just copy and paste them to the devices browser. Http (OpenAI) (1.3).bos
Hey,
I updated the template to GPT-4-preview model - old legacy model is still there but request data for gpt4 changed a little.
Http (OpenAI) (1.4) for public.bos
Few changes: Added gpt-4o model, fine-tuning settings and disable/enable button when http driver should disconnect.
Http (OpenAI) (1.5) for public.bos
Added gpt-4o vision - Http (OpenAI) (1.6) for public.bos
Image url should have a link in it...
Input: should be text input, something the bot needs to find or look at...
Hello Jurgen! Nice job! I tried to download the file and I set my own API key but when I run the request the HTTP connection goes offline. And the status code shows 429. I run the integration against a free account at Open AI.
Hey, Check if the free account has a balance - They give 15eur for free and then you have to pay to use the API. 429 code means that there were too many requests, not sure if it shows the same error when the balance is at 0. Also when making text requests try to keep it on one line. It may fail if you send the string on a new line from bOS client.
Right now i'm having also strange problems - I tried to make translations for bOS, and now it just crashes the webpage after about 50 translations... So not sure if they are having general troubles right now or not, yesterday it worked better for me. With gpt-4o translating about 1200 indexes(Eng to Estonian and Russian) costed me about 10 euros.
Edit: Just tested that mine still works in bOS. Also you may need to change the timeout values if you request bigger texts.
HEMS is one of the things that will be very greatto have on Home automation .
When it comes to manage max power demand and heating EV charging etc
If we can feedin Historical data and let IA decide what time It will turn on heating or charge my car thats great
look forward for the changes this will open for CC
So there's a new kid on the block. More info on its API can be found here: https://github.com/ollama/ollama/blob/main/docs/api.md#api
I made a quick and dirty template for it, do what ever you like with it. And it is running locally and it is able to communicate with bOS. Deepseek-r1 template v0.01
Deepseek Template for bOS: The Ultimate Guide (or at least a "decent" one)
Introduction
Congratulations! You've just acquired the legendary Deepseek template for bOS. This isn't just any template—it's the template. It seeks, it finds, and sometimes, it even works on the first try! (No guarantees, though.)
Getting Started
Installing Ollama on Windows (So Deepseek Can Actually Work)
installer for Windows from the official site. If you end up on a shady website offering "free bonus tools," reconsider your choices.
This will download Deepseek-r1 or what ever model you choose. Yes, it might take a while. No, you don’t need to stare at the progress bar (but we know you will).
If all goes well, you should see some text output instead of errors. Congrats, you’re halfway there!
Configuring Deepseek in bOS
localhost and default port 11434If it's on another machine, change the IP in the settings. (No,192.168.1.1is not always the right answer.)Troubleshooting (a.k.a. “Why is this not working?”)
Final Thoughts
You are now the proud user of the Deepseek template. Will it change your life? Probably not. But it might make bOS a little bit smarter, and that’s a win in our book.
Good luck, and may your smart home always obey your commands (eventually). Tutorial made by it's competitor ChatGPT
Http Ollama-deepseek-r1 (0.02).bos
Fixed some errors and made a main control panel. Also added model Pull request. Still a lot to do.
Hello Jurgen,
as always, great work on the integration! Will test it out internally as well and post the example (with your credit of course) to our website for all to use!
Best regards, Support team
It's not done yet, so it's still too raw to share, but I'm happy to let anyone contribute, edit, and test it. I even forgot to add the DeepSeek-R1 model to the list, so there's still a lot of work to do. But I did include all the other DeepSeek models, making it easy to switch between them for testing.
What I love about it is that it runs locally, and it's surprisingly good at answering my stupid questions.
Also, I couldn't get chat streaming to work. It would be awesome if users could see the bot's "Thinking" process, as there's a lot of back-and-forth reasoning happening, and it's fun to watch. Is there a way to get streaming to work with the HTTP driver so it stays connected for about five minutes?
Hello Jurgen,
So right out of the bat, when i started sending out commands, the HTTP driver would automatically disconnect, i think it had issues with the model number selection list. If i ran the /api/tags, to get the model number i could get the response for the model number to be : deepseek-r1:latest.. So i created a new string with deepseek-r1:latest as value and use this in the Send command to always try to use the "latest model".
Which seemed fix the issue and all the commands seem to work ok now. It does take quite some time to get an answer (for me it's like 30s.. How's it like on your end?
Best regards.
Yep I added the model later on, didnt update the template in here tho(Edit button went missing by that time). I've only tested deepseek-r1:14b and 9b so far. I haven't timed the responses yet but it isnt that bad under 5 minutes usually(20,76s without stream with 14b) it would show its thinking part sooner if the streaming flag would be true. Ollama is running on a 5950x and 3080ti right now so it is what it is. If you run it without an GPU then it will be a lot slower.
Hello Jurgen,
Ah i see what's going on.. So the longer the response, the more time we wait. For general chatting, it's quite slow at this point, even in PowerShell... To get a full response, in some cases we wait a minute or two to finish everything..
Same goes in bOS.. If the response is very long, we wait till it finishes.. then post the response.. Which in some cases feels like it's not working.. but a minute or so later, we get a response.
For what it is at this point, it seems to work quite well! Just a bit slow :)
Best regards.
Maybe you can look into the http streaming. If streaming=true it would be faster. Here is a same prompt for a joke made 4 times. Times are different even if the prompt is the same.
llama_new_context_with_model: KV self size = 384.00 MiB, K (f16): 192.00 MiB, V (f16): 192.00 MiB
llama_new_context_with_model: CUDA_Host output buffer size = 0.60 MiB
llama_new_context_with_model: CUDA0 compute buffer size = 307.00 MiB
llama_new_context_with_model: CUDA_Host compute buffer size = 14.01 MiB
llama_new_context_with_model: graph nodes = 1686
llama_new_context_with_model: graph splits = 2
time=2025-01-30T13:40:57.000+02:00 level=INFO source=server.go:594 msg="llama runner started in 3.26 seconds"
[GIN] 2025/01/30 - 13:40:58 | 200 | 3m41s | 192.168.1.100 | POST "/api/chat" I think this was a bug as i had it paused in PS - it calculated both jokes and sent them out together. Usually for a small joke it takes 5-7s
[GIN] 2025/01/30 - 13:40:59 | 200 | 2m20s | 192.168.1.100 | POST "/api/chat"
[GIN] 2025/01/30 - 13:41:02 | 200 | 18.1981495s | 192.168.1.100 | POST "/api/chat"
[GIN] 2025/01/30 - 13:43:50 | 200 | 52.7484304s | 192.168.1.100 | POST "/api/chat"
Http (OpenAI) (1.7) for public.bos
Made few changes. Added some more fine tuning options. Also the new gpt4.5 model.
Http Ollama-deepseek-r1 (0.05).bos
Added Vision Support
The feature currently works with BakLLaVA and LLaVA models. To use it, you’ll first need to download/pull one of these models.
Image Format Requirements
Images must be provided in base64 format rather than as URLs hopefully it will change in upcoming updates. However, during testing in PS, links appeared to work inconsistently—this discrepancy between direct testing and API behavior is still under investigation.
Current Focus
I’m exploring methods to implement base64 encoding exclusively within bOS.
Http Ollama-deepseek-r1 (0.06).bos
Setting Up Open-WebUI for Ollama Integration (With/Without Apache Proxy)
I recently integrated Open-WebUI with Ollama to create an enhanced user interface with a streamlined experience. The system is fully operational for core functions, including file uploads and text-to-speech (TTS), though microphone input (speech-to-text) remains unresolved.
1. Installation Overview
Installed locally via
pip(non-Docker) on the primary server, running on port8080.Note: Multiple installation methods exist – this pip-based approach was chosen for simplicity.
A Raspberry Pi running Apache handles HTTPS traffic forwarding to Open-WebUI.
Why? Modern Android WebView blocks HTTP connections – HTTPS via proxy ensures mobile compatibility.
2. Accessing the Interface
https://your-domain.com:1443Direct LAN access via
http://localhost:8080(compatible with internal bOS for windows browser. I had problems on Android so proxy was needed)or
http://[server-IP]:8080from local network devices3. Functional Features
Successfully integrated for image analysis
Limitation on API: Base64 encoding still required for API-based image processing
4. Current Limitations
Non-functional
Anyways it looks a lot better this way and does not have bOS quirks.
Also sharing my prompt for easier translations for bOS. I use Gemma3:12b with Ollama/OWUI and it works quite well. 10 indexes take about 1-2 minutes.
Setting: Temperature: 0 (Less errors)
num_gpu (Ollama): 256 (depends on your system)
Prompt, change it as needed for you - I needed translations for EN, ET and RU: